請輸入想查詢的單字或片語
dataset
US /'deɪtəset/
・UK /'deɪtəset/
A1 初級
n.名詞資料組
影片字幕
AI 再進化!全新AI模型EMO只要影片跟聲音就能生成對嘴動態影片 (EMO: The New AI That Really Shocked The Internet! This is why...)


羨慕朋友的朋友好像比較多,比較受歡迎嗎?修但幾勒!先了解什麼是「友誼悖論」! (Why Your Friends Have More Friends Than You)

- There's a Facebook dataset collected by Stanford with data from 4000 volunteers.
斯坦福收集的一份Facebook數據集,其中包含了來自4000名志願者的數據。

中英字幕】NVIDIA GTC 2025發表機器人12分鐘全精華!黃仁勳 Keynote 點名的下一個大市場 (【中英字幕】NVIDIA GTC 2025發表機器人12分鐘全精華!黃仁勳 Keynote 點名的下一個大市場)

- Developers use Isaac Lab to post-train the robot policies with the augmented dataset, and let the robots learn new skills by cloning behaviors through imitation learning, or through trial and error with reinforcement learning AI feedback.
開發人員利用 Isaac 實驗室使用增強數據集對機器人策略進行後期培訓,讓機器人通過模仿學習克隆行為,或通過強化學習人工智能反饋進行試錯,從而學習新技能。
中英大字幕 | 15分鐘掌握最新科技動態 | 黃仁勳揭露未來最大產業是它 | 2025 GTC 最重要的發表 (中英大字幕 | 15分鐘掌握最新科技動態 | 黃仁勳揭露未來最大產業是它 | 2025 GTC 最重要的發表)

- Developers use Isaac Lab to post-train the robot policies with the augmented dataset, and let the robots learn new skills by cloning behaviors through imitation learning or through trial and error with reinforcement learning AI feedback.
開發人員利用 Isaac 實驗室使用增強數據集對機器人策略進行後期培訓,讓機器人通過模仿學習克隆行為,或通過強化學習人工智能反饋進行試錯來學習新技能。
醫療保健數據分析師應瞭解的 4 種類型 (4 Types of Healthcare Data Analysts Should Know)

- I also have an entire one-hour lesson dedicated to learning the basics of SQL with EMR data using a synthetic dataset called Cynthia.
我還有一整節一小時的課程,專門使用名為 Cynthia 的合成數據集,通過 EMR 數據學習 SQL 的基礎知識。
大型語言模型介紹 (Introduction to large language models)

- First is the enormous size of the training dataset, sometimes at the petabyte scale.
首先是訓練數據集的巨大規模,有時甚至達到 PB 級。
- This leads to the last point, pre-trained and fine-tuned, meaning to pre-train a large language model for a general purpose with a large dataset and then fine-tune it for specific aims with a much smaller dataset.
這就引出了最後一點,預訓練和微調,即使用大型數據集為通用目的預訓練大型語言模型,然後使用小得多的數據集為特定目的進行微調。
用於自動量化 HER2 擴增水準的細胞實例分割技術 (Cell Instance Segmentation for Automated quantifcation of HER2 amplification levels)
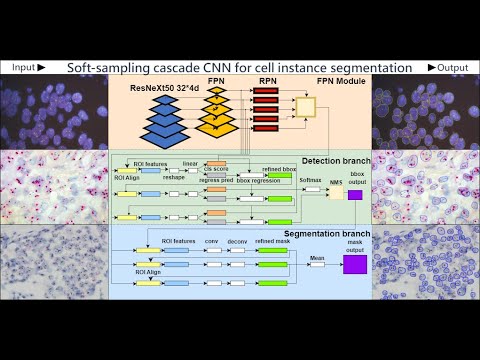
- Quantitative results the proposed cell instance segmentation model outperforms 10 baseline models in F1 score on the FISH breast cancer dataset and seven baseline models in F1 score on THE DISH breast cancer dataset while also showing promising predictive results on the DISH stomach cancer dataset.
量化結果我們提出的細胞個體分割模型在 FISH 乳癌資料集的 F1 分數上優於 10 個基準模型,在 DISH 乳癌資料集的 F1 分數上優於 7 個基準模型,同時在 DISH 胃癌資料集上也展現出有前景的預測結果。
但人工智能影像和視頻究竟是如何工作的?| 韋爾奇實驗室特邀視頻 (But how do AI images and videos actually work? | Guest video by Welch Labs)

- In February 2021, a team at OpenAI released a new model architecture called CLIP, trained on a dataset of 400 million image and caption pairs scraped from the internet.
2021 年 2 月,OpenAI 的一個團隊發佈了一個名為 CLIP 的新模型架構,該架構是在一個由從互聯網上搜羅的 4 億張圖片和標題對組成的數據集上訓練出來的。
- In our toy 2D dataset, where the coordinates of a point correspond to that image's pixel intensity values, adding random noise is equivalent to taking a step in a randomly chosen direction.
在我們的玩具二維數據集中,一個點的座標與該影像的像素強度值相對應,添加隨機噪聲相當於向隨機選擇的方向邁出一步。